The internet's infrastructure is more fragile than anyone wants to admit
From AWS's 15-hour DynamoDB disaster to PlayStation's 24-hour lockout, 2025 saw record internet outages. Here's what broke and why it matters.


2025 proved that even the internet's biggest players aren't immune to catastrophic failures. According to data from Downdetector (owned by Ookla), this year saw some of the most widespread service disruptions in recent history, with outages affecting everything from gaming platforms to critical cloud infrastructure.
But here's what made 2025 different: the failures weren't just bigger. They were more revealing. Each major outage exposed how much of the internet runs on a handful of services, and what happens when those services go sideways.
KEY TAKEAWAYS
- AWS suffered the year's largest outage with 17 million+ reports after a DNS failure took down DynamoDB for 15 hours
- PlayStation Network's 24-hour outage affected 116 million users, making it the second-longest PSN downtime in history
- Cloudflare's five-hour disruption impacted 3.3 million services, from ChatGPT to Spotify
- Du telecommunications in UAE recorded 28,444 outage reports in February
- The outages highlight dangerous dependence on centralised cloud infrastructure with single points of failure
AWS Went Down and Took 17 Million Services With It
October 20, 2025, started like any other day. By 3 AM ET, it was clear something had gone very wrong with Amazon Web Services' US-EAST-1 region. What began as "increased error rates and latencies" turned into a 15-hour nightmare that generated over 17 million outage reports across Downdetector.
The culprit? A DNS race condition in DynamoDB's automated management system. For those who don't speak tech: DynamoDB is a database service that many AWS tools rely on to function. When its DNS records got wiped out by competing automated processes, it essentially disappeared from the internet. Services couldn't find it. Requests failed. Everything cascaded.
Apps like Snapchat, Netflix, Alexa, Coinbase, and Fortnite went dark simultaneously. But the real problem wasn't just external services. AWS's own internal systems depended on DynamoDB. When it failed, critical infrastructure like EC2 (the service that powers virtual servers) couldn't track which physical machines were available. The result: "insufficient capacity" errors even though the hardware was fine.
Engineers identified the DNS issue by 7.26 AM UTC and implemented temporary fixes by 8.15 AM. But bringing DNS back online didn't immediately solve the problem. EC2's lease management system had fallen into what AWS called a "congestive collapse" - retry requests piling up faster than the system could process them. Full recovery didn't happen until 3.01 PM PDT, over 15 hours after the initial failure.
According to insurance analysts at CyberCube, the estimated losses from this single outage could reach $581 million. AWS has since disabled the faulty automation globally and is rebuilding it with better safeguards. But the damage to confidence was done.
| Service | Date | Duration | Reports | Region | Cause | Impact |
|---|---|---|---|---|---|---|
| AWS (Amazon Web Services) | Oct 20 | 15 hours | 17M+ | Global (US-EAST-1) | DNS race condition in DynamoDB | Snapchat, Netflix, Alexa, Coinbase, Fortnite offline. Estimated $581M losses |
| PlayStation Network | Feb 7-8 | 24 hours | 3.9M | Global | Operational issue (undisclosed) | 116M users locked out. Call of Duty, Fortnite, Destiny 2 unplayable |
| Cloudflare | Nov 18 | 5 hours | 3.3M | Global | Configuration issue | Spotify, ChatGPT, Discord, Truth Social offline |
| Du (UAE) | Feb 8 | — | 28,444 | Middle East | Major telecom disruption | Regional telecommunications affected |
| Snapchat (MEA) | Oct 20 | — | 26,392 | Middle East & Africa | Linked to AWS outage | Social media platform disrupted regionally |
| Cloudflare (MEA) | Nov 18 | 5 hours | 28,016 | Middle East & Africa | Global outage impact | Cloud services disrupted across MEA |
PlayStation Network Locked Out 116 Million Gamers
Friday evening, February 7, 2025, at roughly 6 PM ET. PlayStation Network went offline. All of it. PS5, PS4, PS3, PS Vita, mobile apps, the PlayStation Store website. Everything.
Over 3.9 million people reported the outage to Downdetector, making it the second-largest global outage of the year. For context, PlayStation Network has an estimated 116 million monthly active users. A significant chunk of them couldn't play games, buy content, or access their accounts for nearly 24 hours.
The timing was brutal. The Monster Hunter Wilds beta launched that same day. PlayStation users were locked out while Xbox and PC players carried on. Major titles like Call of Duty: Black Ops 6, Fortnite, and Destiny 2 became unplayable. Some users reported that even single-player games wouldn't launch, and physical disc drives stopped working - effectively bricking consoles for anyone who hadn't previously validated their games.
Sony's communication was minimal. The @AskPlayStation account posted a vague acknowledgement at 8.46 PM ET: "some users might be currently experiencing issues with PSN." That was it. No timeline. No explanation. No estimated fix.
Services finally came back online on the evening of February 8. Sony later attributed the outage to an "operational issue" - corporate speak for "we're not telling you what broke." The company offered PS Plus subscribers an extra five days of service as compensation. Free-to-play users who were also affected got nothing.
The 24-hour downtime made this the second-longest PSN outage ever, beaten only by the infamous 2011 hack that kept services offline for 23 days and cost Sony over $170 million in losses and legal settlements.
Cloudflare Brought Down 3.3 Million Services
November 18, 2025. Cloudflare, the infrastructure service that handles 81 million HTTP requests per second on average, experienced a global disruption lasting nearly five hours. The result: over 3.3 million outage reports across all impacted services.
Cloudflare's reach is hard to overstate. Websites, apps, and APIs across the internet rely on its content delivery network, DDoS protection, and DNS services. When it went down, services from Spotify to ChatGPT to Truth Social all went offline simultaneously.
The outage wasn't caused by a cyberattack. According to Cloudflare's statement, it was a technical issue - most likely a configuration change that cascaded across their systems. But the impact highlighted an uncomfortable reality: much of the internet's infrastructure depends on just a few companies. When one fails, millions of sites become unreachable.
Issues submitted to Downdetector during the outage exceeded 2.1 million reports, according to data provided by Ookla. The sheer scale of dependent services made this the third-largest global outage of 2025.
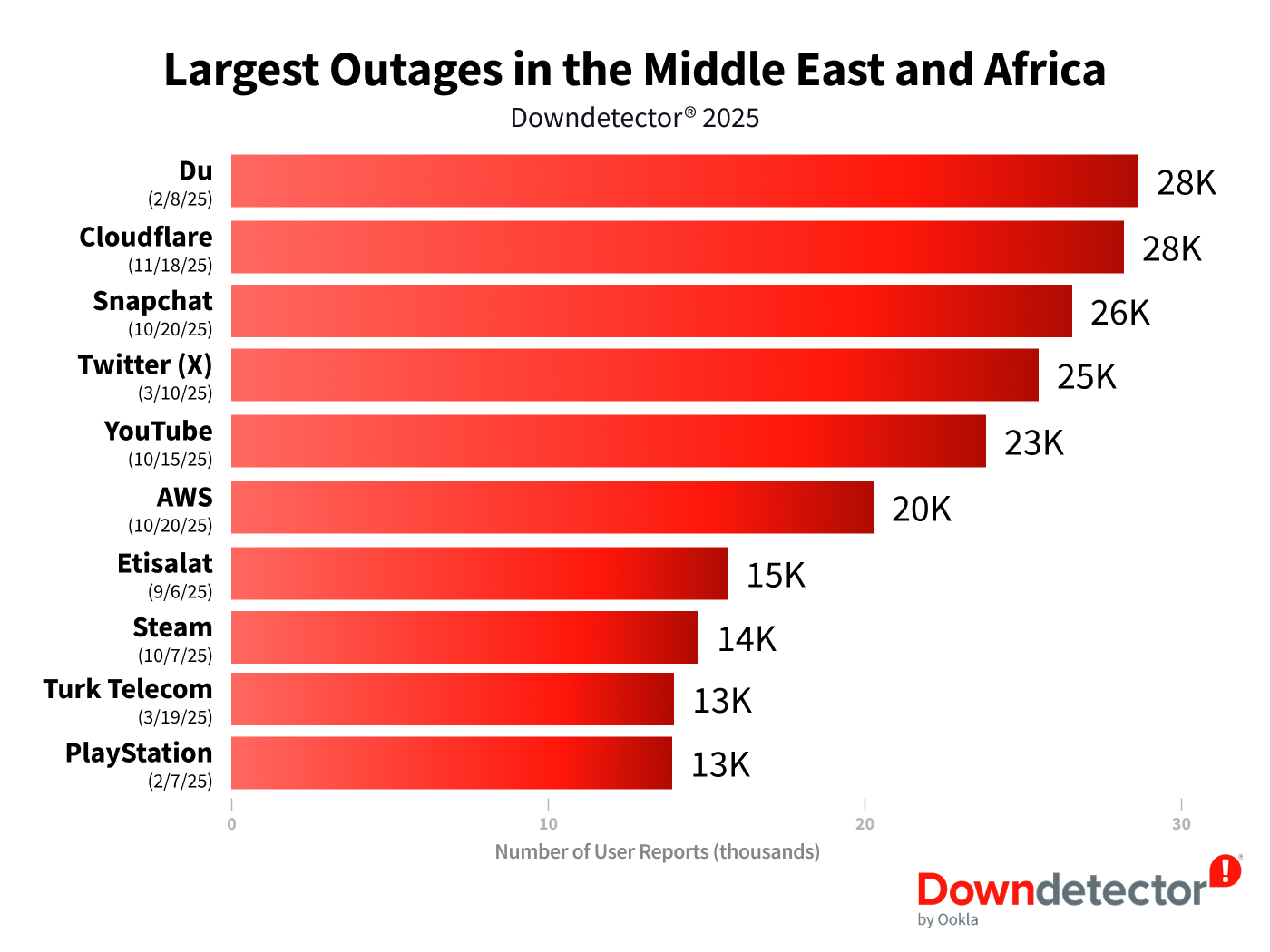
The UAE Felt It Too
The Middle East and Africa didn't escape 2025's outage epidemic. Du telecommunications experienced a major disruption on February 8, recording 28,444 reports. The Cloudflare outage also hit the region hard, with 28,016 reports in MEA during the November incident.
Snapchat's October 20 disruption generated 26,392 reports in the region - notably coinciding with the AWS outage, suggesting many services in the region run on AWS infrastructure in US-EAST-1.
These regional numbers reveal something important: outages that start in one geographic region can ripple globally when services depend on centralised infrastructure. A DNS failure in AWS's Virginia data centre affects Dubai just as much as Dallas.
Why This Keeps Happening
According to Cisco ThousandEyes, the number of outages hasn't actually increased. What's changed is the scale of impact. More sites and applications depend on fewer providers, making each outage more disruptive.
Cisco's network monitoring logged 12 major outages in 2025 so far. Common patterns emerged: systems accidentally spreading tech failures, silent issues that appeared functional but weren't, and configuration changes that cascaded. None of these are new problems. But as Cisco notes, they're seeing "more of these types of disruptions with more far-reaching consequences."
The root cause is consolidation. AWS controls roughly 30% of the global cloud market. Cloudflare handles 81 million requests per second. PlayStation Network serves 116 million monthly users. When infrastructure is concentrated in the hands of a few providers, single points of failure become catastrophic.
Werner Vogels, Amazon's CTO, famously said: "Everything fails all the time." He's right. But in 2025, we learned that when everything depends on the same few things, those failures stop being isolated incidents and become internet-wide disasters.
The question isn't whether more outages will happen. They will. The question is whether companies will build redundancy and failover systems before the next one, or keep relying on single providers until another 15-hour outage costs them half a billion dollars.
FAQs
What caused the AWS outage in October 2025?
A DNS race condition in DynamoDB's automated management system wiped out DNS records, making the database service unreachable. This triggered cascading failures across AWS services like EC2, Lambda, and Network Load Balancers. The initial DNS issue was fixed within 3 hours, but full recovery took 15 hours as engineers dealt with "congestive collapse" in systems that had piled up millions of retry requests.
How long was PlayStation Network down in February 2025?
PlayStation Network was offline for approximately 24 hours, from February 7 at 6 PM ET until February 8 evening. This made it the second-longest PSN outage in history, surpassed only by the 2011 hack that lasted 23 days. Sony attributed it to an "operational issue" but provided no technical details.
Which services were affected by the Cloudflare outage?
The November 18 Cloudflare outage impacted millions of websites and services, including Spotify, ChatGPT, Discord, and Truth Social. Any service relying on Cloudflare's CDN, DDoS protection, or DNS services experienced disruptions. The outage lasted nearly five hours and generated over 3.3 million reports across affected platforms.
What were the largest outages in the UAE in 2025?
Du Telecommunications recorded the largest UAE-specific outage with 28,444 reports on February 8. The Cloudflare outage generated 28,016 reports in the Middle East and Africa region. Snapchat's October disruption saw 26,392 reports in MEA, coinciding with the AWS outage.
How can companies protect against cloud provider outages?
Multi-region redundancy is essential - run critical services in at least two AWS regions or across multiple cloud providers. Implement automatic failover systems that switch to backup infrastructure when primary systems fail. Keep DNS, secrets management, and monitoring tools independent from your main cloud provider. Most importantly, understand your dependency map and have incident response playbooks ready before outages occur.
Written by

Subscribe to our newsletter
Subscribe to our newsletter to get the latest updates and news













Member discussion